The idea
One morning I had a bland, burnt egg and half a croissant that didn’t survive the toaster oven. The day before, I’d been working on image generation for volunteering — prompting a burger and a glass of pop overlooking a scenic landscape. I was struggling with camera angles and perspectives.
Then I thought, maybe the real challenge isn’t making food look good—it’s capturing something that looks as unappetizing as my breakfast.
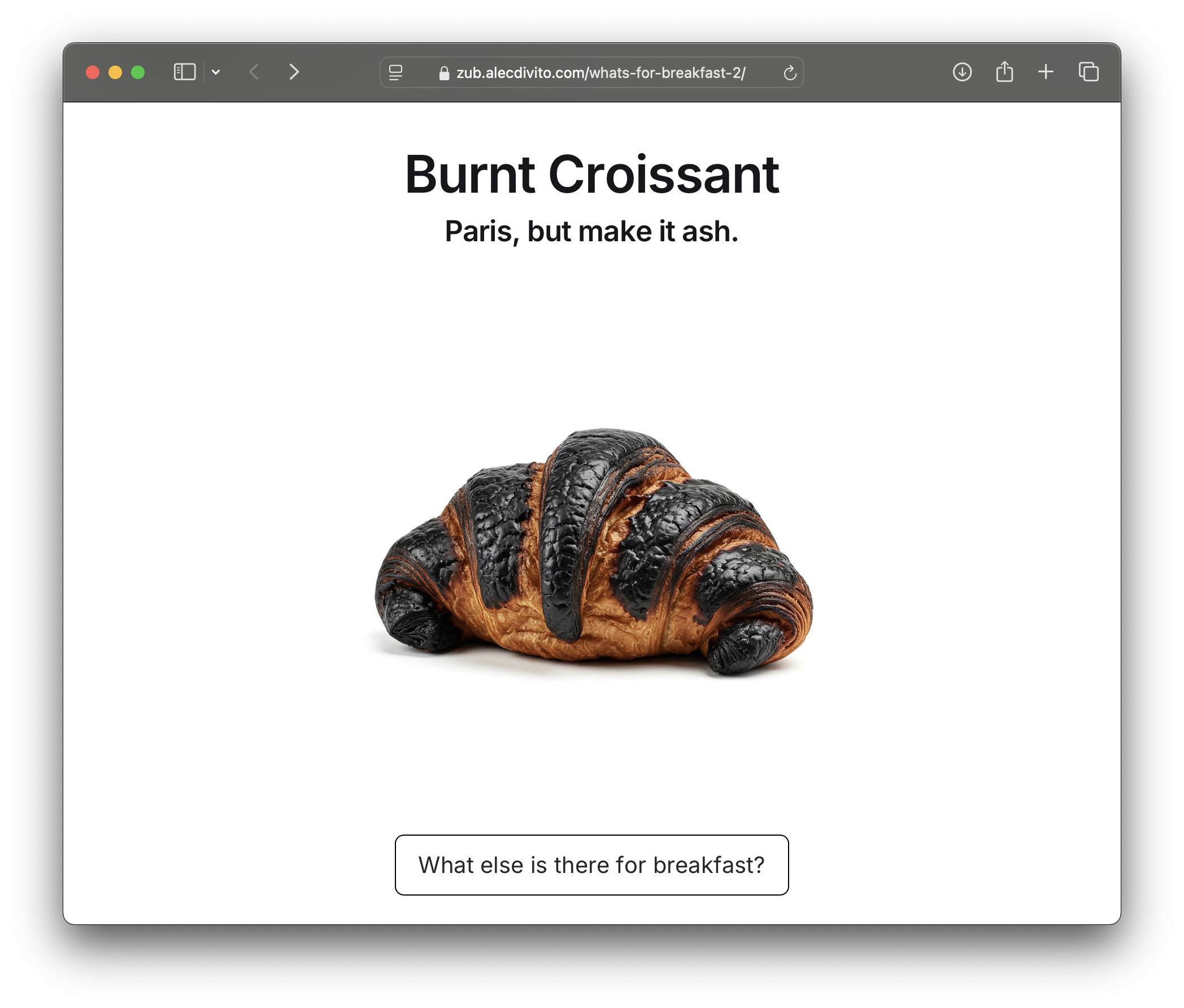
What's for breakfast?
Heads up!
There is some unpleasant food imagery, generated with AI.
Prompting for consistency
ChatGPT gave me a list of 20 common and sad breakfast ideas, from burnt eggs, to pop tart in water and melted ice cream. I knew I wanted to generate over 10 images and try it all. I also knew I wanted them to look consistent: light, angle, relative size, position.
This prompt helped me with achieving consistent results and save time on editing:
Gemini's love language is ✨ perfection ✨
Unless I specified the unappetizing details, the model kept generating perfect-looking food. Words like "second day," "dry," or "sad" didn’t really register with Gemini. So I started building a vocabulary of what actually makes food look unappealing. I had just canceled my ChatGPT subscription, so I was sticking it out with Gemini for now.




A toast with cucumbers, a roll of a cheese slice, rice with Doritos and a drizzle of hot sauce.
Prompting for imperfection
Who hasn’t had eggs for breakfast? I’ve had more than my share of overcooked ones—despite liking them sunny side up and runny. Funny how I assumed my version of “unappetizing” was universal. (Hello, bias!) Turns out, I had to be pretty specific about how I wanted my egg to look burnt.






Taking prompts too literally
Describing things with context can be a fun and unexpected way to generate images, and it often leads to some very interesting and surprising results.
Prompt below put the chocolate bar literally under the bed.



It’s hard to be mad when the model gives you something totally unexpected—especially when it somehow does match your prompt and makes you laugh in the process.
Unappetizing fast food is a challenge
Creating an image of unappetizing fast food is surprisingly difficult. For one, it’s designed to look appealing—bright colors, perfect proportions, glossy textures. And beyond that, our brains are wired to associate burgers and fries with indulgence, comfort, and satisfaction. It takes some serious prompting to break that illusion.





It wasn’t until a few generations in that I realized the prompt was actually encouraging proper lighting and composition—things that naturally enhance a food’s texture and color. To get the result I wanted, I had to tweak the prompt to intentionally make the food look dull or unappealing—without making it look like a bad image overall.
What about switching models?
Turns out, ChatGPT with DALL·E is surprisingly good at personifying feelings in objects. I only had to prompt once, and this is by far the saddest image of greens and fast food I’ve managed to get. Just look at that salad face—pure veggie despair.


Composition and fitting objects into the view
After countless tries, I still couldn’t figure out the right prompt to get all the objects to fit into view. Most of the time, Gemini insisted on placing forks and knives awkwardly outside the frame. Even adding “fit all objects into view” didn’t seem to help. And since Gemini doesn’t support incremental changes, I had to keep resending the same prompt (sometimes out of pure stubbornness) only to get a completely new image each time.





Issue persisted with a spoon of peanut butter
Composition turned into a real challenge when I tried to create an image of a spoon with peanut butter on it. After some trial and error—mostly tweaking the word order—I finally got lucky and managed to get the spoon fully in view:






Controlling liquid level
It's ether full, or empty, I could not get Gemini to do 1/3 of a container of any liquid kind.





Pizza crust
After over 12 tries, Gemini still couldn’t manage to generate a pizza crust! I even provided references, but no luck. I didn’t realize I was capable of describing leftover pizza crust in so many details.
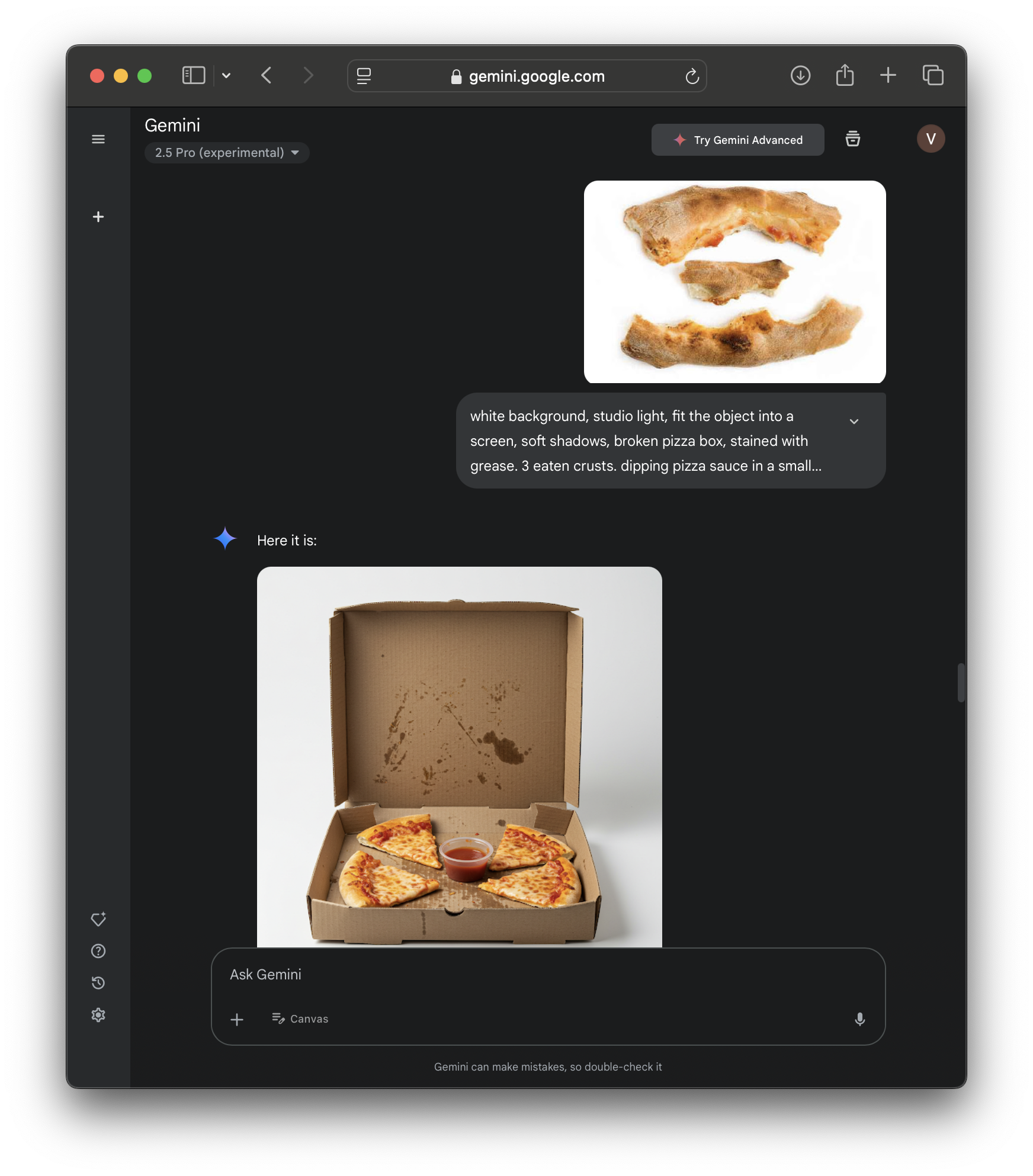






Discovering appropriate prompting and slowly getting there with ChatGPT DALL-E!
ChatGPT DALL-E knew that crust was, it was failing to recreate bite marks, so I asked it for exactly that, then sprinkled some toppings on it.




Studio lightning will make things look better
I was leading my prompts with “studio light, white background” to keep things consistent. Even though the food still looked dull, the images remained relatively positive. The first two images were generated by Gemini, then fed into ChatGPT. While the composition and groceries stayed the same, it was the lighting that really shifted the mood of the image.



Editing images
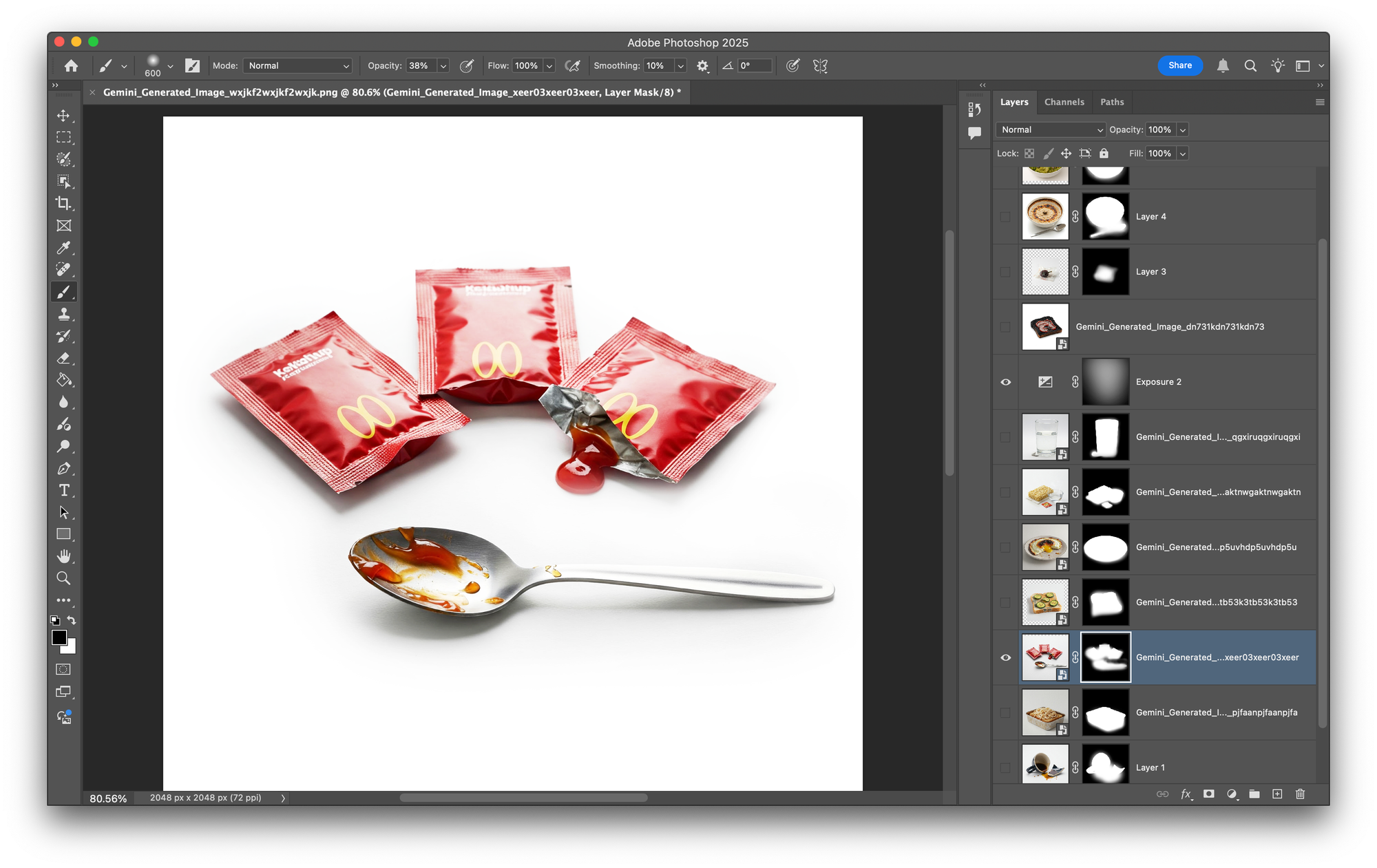
Consistency was the goal since the beginning of the project, so I picked images that looked well together. However, many of them required background removal and some colour adjustment.

Photoshopping with florafauna.ai
I was curious if AI would also be able to photoshop my images. Flora is a web tool for combining imagery using the same AI models. Unfortunately, the background removal was too rigid. It would remove objects entirely, or overexpose the image. Maybe I wasn’t prompting it right, as it didn’t quite work as I’d hoped.
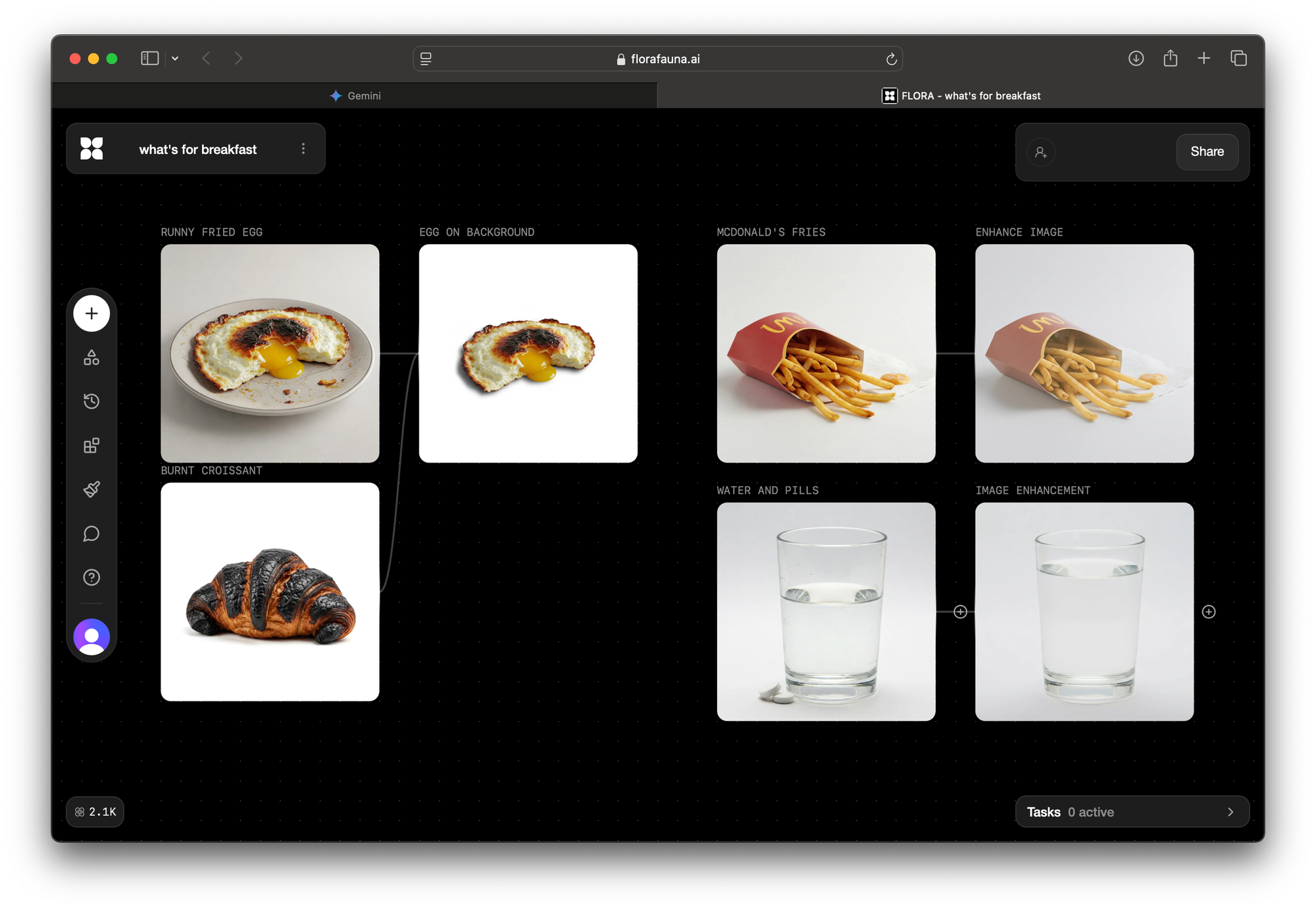
update ~ Just a week later they released background removal feature
Oh well haha
At this point I wanted wrap this project up, a quick background removal in a familiar tool and a mask helped me with achieving consistency across images.
Conclusion: Gemini VS ChatGpt DALL-E
I believe these two images perfectly summarize the differences in generating unappetizing food. Gemini Flash can create stunning, photorealistic images in high quality within seconds. On the other hand, ChatGPT DALL-E takes about a minute to produce a lower-resolution, high-noise image, yet a very creative oddly crushed croissant.


Left: Gemini generated image of a crushed croissant, right - ChatGPT DALL-E
Gemini
✅ Free!
✅ 2-5 second image generation when available
✅ Photorealistic
❌ Inconsistent image re-generation when correcting small details
❌ 1:1 aspect ratio
ChatGPT DALL-E
✅ Consistent image re-generation when correcting small details
✅ Customizable aspect ratio
✅ More creative with generating imperfections
❌ Much lower image quality, high noise in poor illuminated images
❌ Limited free image generation
If you need imperfection in your imagery I would highly recommend going along with DALL-E if you're willing to pay. Else buckle up to discover millions of way to describe the imperfection you're imagining with Gemini.
A few images that did not make it
Noodles on a bill, leaky banana standing up right (why?), and dried cucumbers on a moldy toast.



What's for breakfast?
Want to try it yourself?
I encourage you to try out some silly ideas, here is some ideas I wish I had spent more time on:
- Try deconstructing meals, it is always SO hard to make a breakfast
- Broken cutlery, spilled liquids
- Moldy or dried out fruits and vegetables
Have fun!